A couple of weeks back at Episode 29 of the In Tech We Trust podcast we talked about the the failure rate of flash drives. Apparently, when handled by smart controllers, it is far less likely than we would think. Some DMs with Vaughn Stewart (Chief Evangelist at PureStorage) later we came to the following statement:
The failure rate of flash drives at PureStorage, 2.5 years after GA, is less than 10 in 1000’s of deployed drives.
This is a truly impressive number. It also helps understand why SolidFire announced “an unlimited drive wear guarantee valid for all systems under current support”. (source: The Register)
The Rebuild
Having a failed disk is not necessarily an issue. We have failover mechanisms for that. The problem is the consequenses of rebuild time. First of all there is the risk of double failure since we put extra stress on the disks for rebuilding parity. That’s why we have created double parity solutions (RAID6). Secondly there is a significant performance drop since both the controllers and the disks are ‘busy’ working on that rebuild. This resulted in up to 24/48hr of keeping your fingers crossed.
Does this still apply for all-flash systems? I mean, isn’t a flash drive exponentially faster than a hard disk? Let’s put it to the test, shall we?
Put it to the test
A friend of mine told me they had a PureStorage system in Proof of Concept (PoC). So I asked them if they’d run a couple of tests for me.
Disclaimer: PureStorage had no knowledge of these tests so had no ability to turn knobs to tweak the test for better results.
The array we have at hand is a PureStorage FA-405 (entry-level) with 3.19 TB usable capacity (before deduplication) and 2x8GB FC per controller. Throughout the test we are pushing 80.000 4k IOps at 50/50 read/write 100% random just to make sure we are putting the necessary stress on the machine. This is by all means not a performance benchmark!
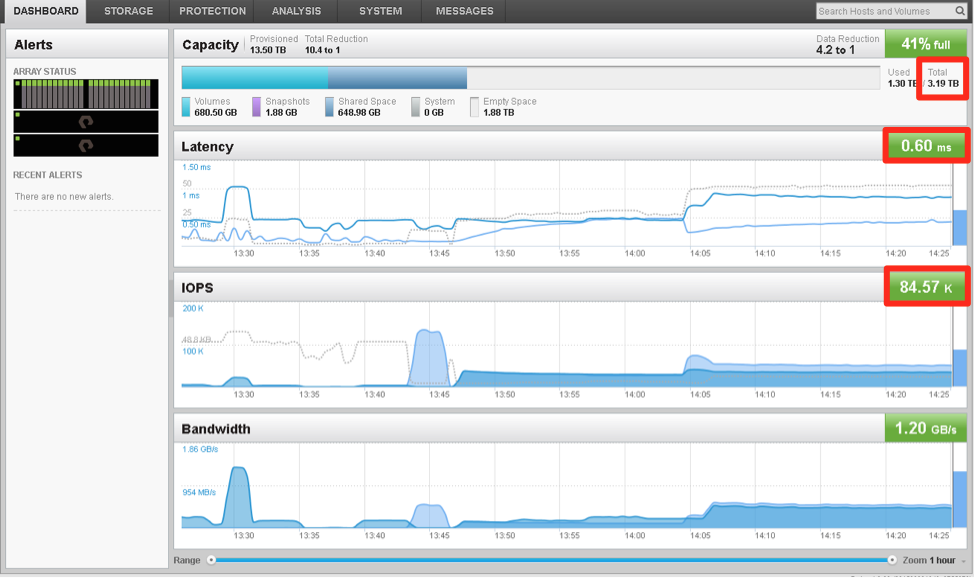
After pulling 2 disks at the same time, we notice a 2 minute drop in performance (45.000 IOps) after which it goes back to full performance.
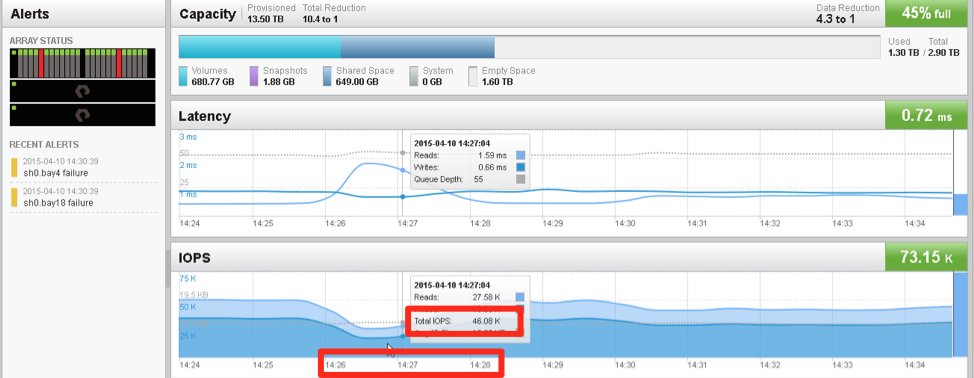
While the system was rebuilding parity on the remaining disks, we pulled a controller. PureStorage works wih an Active/Standby controller mechanism. This is why we notice a short interruption in monitoring because we pulled the active controller. Notice that the performance was NOT impacted at all. And once parity was completely rebuild to 100% (about 45 minutes) we pulled yet 2 more drives (15:15). Because we have 4 drives pulled you will notice that the usable capacity has now dropped to 2.6TB.
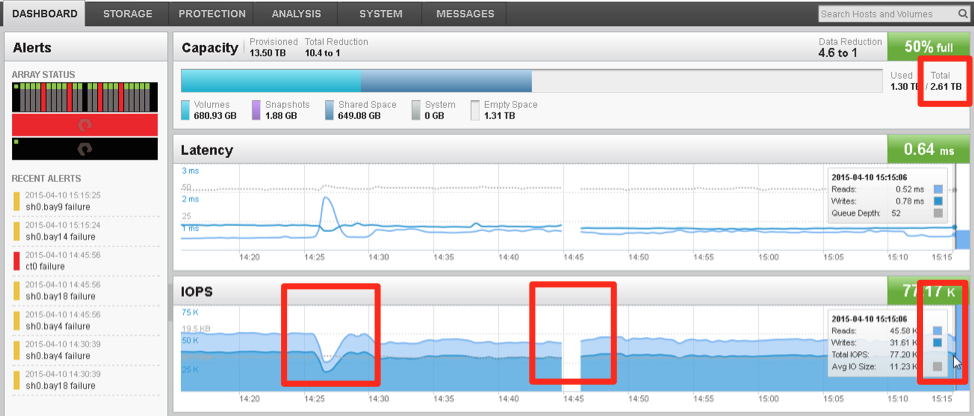
The rebuild of the 2 extra pulled drives to the remaining drives available took another 45 minutes. In the end you have a fully operational and protected array with 18 disks instead of 22. Which means that when we added the 4 pulled drives (in random order and place) we just expanded the array to 3.19TB and was almost immediately available at 100% parity. The array will now take action to rebalance the free space in the background.
Summary
Back on topic! Anyone that ever had to replace hard disks in a storage array will understand that doing all these risky moves and being back to square 1 in less than 2 hours is really impressive. Combine this with the statement of a drive failure rate less than 1% in 2.5 years and you’ll have to admit that flash is not only faster but also a lot safer!
In a cache-based hybrid array (so not tiering!) I would also suspect a lower failure rate on HDDs due to the lower stress impact. But in my opinion they will not be able to pull off these short rebuild times. Anyone have one of those in PoC for me? 🙂
Disclaimer: PureStorage has been a client and was a sponsor of TechFieldDay editions I attended where my travel and accomodations were provided by the organizers.
1,3 TB of used capacity results in 60 GB user data per drive (22 drives total). Pulling out two drives means you lost 120 GB of user data in worst case. Rebuilding the data in 45 mins. is okay, since Purity stripes all data against all remaining disks and b/c it has very powerful controllers ! But what about rebuilding disks e.g. the 512 GB SSDs (or in future 1 TB) that are nearly full ? 😉
While you have a point that the working set is not incredibly big, the difference with rebuilding a RAID6 HDD solution is exponential. Don’t forget that we are pushing 80k IOps at 800>1000MB/s as well in the mean time.
Hans, I’m with you ! 😉 We have a Pure in training lab, too. But rebuilding 1 TB takes even on a Pure Storage some time and meanwhile your array is running at risk. Nobody buys an All-Flash array for running non-important workloads. 😉 Classical RAID is an outdated technology and should be replaced fast. Imagine a lost 6 TB SATA disk, the rebuild time can take weeks !!!
The Pure Storage has a very good deduplication and compression rate, too. If a drive fails you loose much more data than the drive can hold. Even if the resiliency of a Pure Storage is very good (and it is good), a failed drive in this system is a high risk and you should replace it as soon as possible. Don’t trust too much in this fancy toy, be prepared (especially if a log drive fails) and then you have lot’s of fun with a Pure Storage array. 🙂
good point – if you look closely to first screenshot you’ll notice we’re at 10:1 already on this test machine.
However, all in all, this is not a blog about PureStorage but merely using them as an example in the bigger discussion of why all-flash over HDD or hybrid and sparkled by the idea that less than 1% of them has failed over the last 2.5 years of production at Pure.
The discussion is NOT all-flash, it’s how to store data in future. In my opinion current all-flash arrays has some potential risks and they should’nt be ignored. Running biiiiiiig SATA disks with RAID-6 is similar stupid, too. 😉
(note: I work at HP, but moved on from HP’s storage business over 6 years ago. Speaking as individual.)
I’m a big supporter of flash, and have been since we realized it was on track to change the storage landscape a dozen years ago. Great to see it happen!
Two areas where taking a quick look can lead a novice astray:
First, a flash drive is a lot like a journaling file system: things work really fast until the drive fills up for the first time, after which garbage collection (analogous to defragmentation on a traditional drive) competes with production workload for the drive’s attention. Performance measurements need to reflect the steady state behavior, not the empty-drive one.
Second, the bane of RAID is correlated failures, that is, multiple drives from the same lot, installed in the same RAID group, failing at essentially the same time. With mechanical drives this was extraordinarily rare. With end-of-life wear-out due to the limited number of times a flash cell can be written, and a workload which tends to write an entire RAID stripe, one of the concerns raised a decade ago was how to avoid all of the drives in a RAID group simultaneously informing the controller that they were worn to the point of no longer having enough working bits to store their rated capacity. A traditional disk array would have responded to an error like that by taking the data offline… don’t know how the industry addressed this one in the end.
I personally ceased talking with one of the pioneers in this area after they waved their hands and emphatically said wear-out was a non-issue. I just want the customer experience to be one of metrics which allow evacuation and replacement of worn out drives to be budgeted and planned maintenance, rather than an unexpected expense (or worse a loss of data incident). And allow selling the right flash parts (for example, more expensive parts which allow orders of magnitude more write/erase cycles, versus the cheapest per-bit parts which allow very few write/erase cycles) for the application.
My SAN is switching to Pure. We write 3 PB a month on a 20 TB usable FA450 and no disk failed. So, you are talking about a very rare scenario. In addition, if a SSD fails, it is a firmware bug most of the time and it gets back in the loop.
Pure is about changing support model mostly.