1) Disk management:
The first part of failover management is still plain old ZFS. It’s the way disks work together, how I/O is handled and how data corruption is avoided.
- Storage Pool: a set of (equally configured) vDEVs
- vDEV: a set of disks with a certain protection level
- RAIDZ: first form of physical disks protection level. Examples:
- RAIDZ-5: 4 disks data, 1 disk parity
- RAIDZ2-6: 4 disks data, 2 disks parity
- RAIDZ3-9: 6 disks data, 3 disks parity
- Mirrored Disks: second form of physical disks protection level. Here too you have multiple choices of failover (dual-mirror, triple-mirror, …)


Physical disk-enclosure failover: if you design smart, you could even design for disk-enclosure failover by aligning the vDEV physical disks vertically (1 per enclosure)
2) System Scale:
The next step is in-system scale. It’s not really high availability but an equally important step in the story going forward. Because you benefit a lot by a bigger bandwith with ZFS you’d want to “scale-out” first inside your system and then go to “scale-up”. Here you find a simplified example of that.
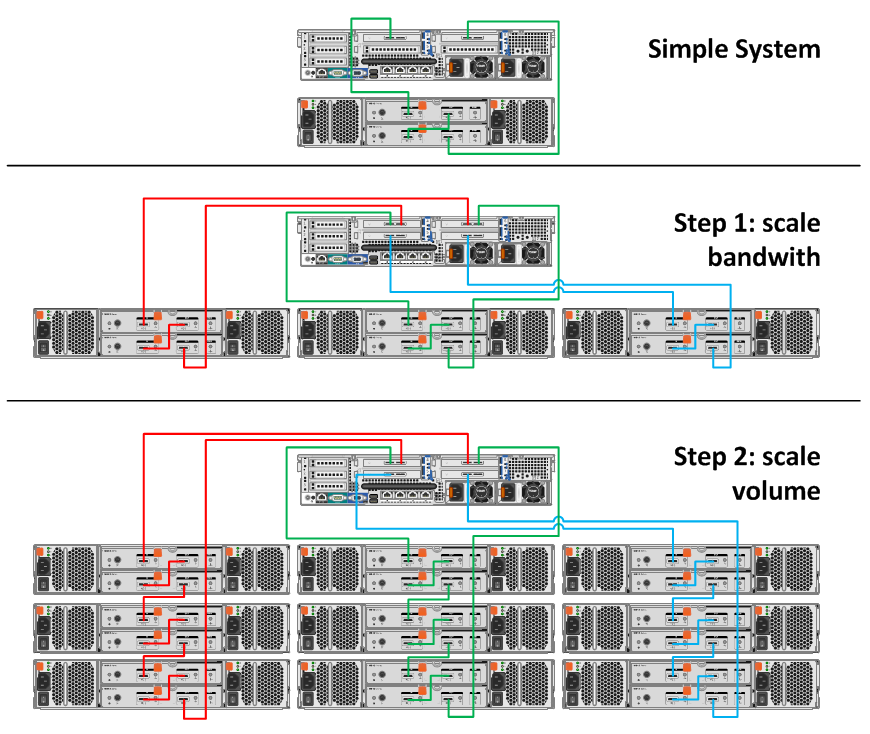
So instead of daisy chaining the 3 first nodes and then adding a second and 3rd loop I did it the other way around so you’d have 3 loops of 6Gbps SAS connectivity from the beginning.
Remark: this is a theoretical model. I would have to doublecheck with the solutions team before designing this for a customer.
2) High Availability Cluster:
As far as you have seen by now I only used 1 controller node and some scale-up possibilities. There is still 1 pretty big single-point-of-failure: the 1 controller node. Nexenta took care of this by adding cluster technology. The basic is: any vDEV is owned by 1 controller but can be accessed by multiple controllers for failover. There are 2 failover parameters used: the first is a disk heartbeat, the other a network heartbeat.

How does this work?
When you add a node to the cluster it needs to be connected to the same jbods and it will be assigned heartbeat disks and a heartbeat ethernet link. When both fail on node1 the second node will notice this and will put an ownership byte on the heartbeat disks (only heartbeat disks since 3.1.3) will take around 20 seconds and will be assigned ownership on the pool and will import the pool. when node 1 comes back online you can switch the vDEVs you want back to node 1. It will not do that on it’s own. It will however take control again in case Node2 would fail.
First thing that popped in my mind is this: where is the IO ack? As you have seen in the previous post the ACK is in the ZIL. So you’ll have to put the ZIL on the JBODs to be able to safely failover at any time. (If you don’t get this, stop reading. You’re not supposed to hear this)’. Although a Nexenta Cluster would have only 2 nodes in a classic HA Cluster they already scale up to 8 nodes if necessary.
Now think crazy, take a whiteboard and some markers ’cause you’re going for a wild ride: there is no boundaries to the connectivity of disks & controllers as long as you can physically manage to connect them. So if you were adding SAS switches or even Ethernet switches (AoE like Coraid) you could en up with real scale-out AND scale-up into petabytes within no-time. I have made one example below:

Right now, you are looking at a 4 controller 500TB (4x120x900GB 10k) scale-out NAS you have build on your own. I did this on DELL hardware because that is something I know best (could have went HP too off course). Only downside here is that little fact that the ZIL SSDs are not on the CPU side of the HBA. Today Nexenta advices the use of STEC ZeusRAM DRAM SSDs. I’ll have to add them somewhere on the JBODs but as I don’t have best-practices experience I’ll keep this one on the theoretical side.
3) Multisite Cluster:
So what happens nowadays when you have multiple sites? Every customer asks you to do Active/Active SAN over 1000 miles distance. You know what? Ain’t going to happen 🙂
No, seriously. Anyone still reading knows by know that we have to educate the customer and his/her demands. So what are the possibilities Nexenta has to offer (technically possible whitin acceptable latency!)
- Autosync (async) replication this replicates the metadata also so it preserves snapshots (preferred choice #1)
- Block level Sync replication with autocdp (CDP = Continous Data Protection). This is sync but please be aware of the latency here.
- Mirror across 2 sites (advanced set-up!). This is a true metro-cluster. I will not elaborate too much here as it is only custom made architecture.
This truly is Enterprise Storage for Everyone. I can assure you that buying this building blocks and adding Nexenta on top is way cheaper than any solution you are going to buy from those big vendors. And on top none of those would have all the features Nexenta has builtin. Think 128bit filesystem, VAAI, NFS4, iSCSI/FC/FCoE/FCoTR, AoE, SMB3 (to come), … Now take this one step further and really buy your stuff off the shelve … $$$ > $$ > $!
MY TAKE-AWAYs:
There are still a few key-points I’d love to see them do differently or at least give you the chance to do so. Example: the fail-over is fine but there is no automatic fail-back. Add an auto-balancing of the vDEVs ownership over all the controllers and you would have a sweet thing out there. Another point in that “peer2peer ownership” is that you’d have to do quite some manual work adding/removing nodes. Like when you want to change on generations of controllers. Wouldn’t it be nice to add 2 new nodes en just ask the software to remove 2 older nodes from the cluster in 1 command?
LINKS:
Nexenta HCL: start designing HERE!
Nexenta LIST prices TIP: buying from a reseller is usually cheaper and if you pick the right one, you’ll get some great consultancy along.
Nexenta Tech Briefs